新着情報
- SHINRA2020-MLの評価結果、システムの実行結果はNTCIR-15: SHINRA2020-ML System Data Downloadで公開しています。(2021/1/8)
- SHINRA2020-MLリーダーボードは復旧しました。(2020/10/19)
- SHINRA2020-ML リーダーボード停止期間についてのお知らせ (10月16日夜〜10月17日午前)。(2020/10/16)
- SHINRA2020-MLリーダーボードは復旧しました。実行結果の提出〆切後もリーダーボードは継続予定です。(2020/8/31)
- SHINRA2020-ML リーダーボード停止期間についてのお知らせ (8月28日〜8月31日午前)。(2020/8/28)
- SHINRA2020-MLのFAQページに2020-JP/ML中間報告会でいただいたご質問を反映しました。(2020/8/5)
- 7月31日に開催した2020-JP/ML中間報告会の録画を公開しました。(2020/8/4)
- 7月31日に2020-JP/ML中間報告会(オンライン)を開催します。是非ご参加ください。(2020/7/29)
- 実行結果の提出ページから結果の提出が可能になりました. (2020/7/10)
- SHINRA2020-MLリーダーボードをリリースしました. (2020/7/6)
- 参加登録&結果提出の締切を8月31日まで延長し(2020/6/30)、タスク参加募集(CFP)を更新しました.(2020/7/1)
- タスク参加募集(CFP)を更新しました.(2020/4/27)
タスク概要
森羅プロジェクトは2017年にスタートしたリソース構築プロジェクトで、Wikipediaの知識を計算機が扱える形に構造化することを目指し、「協働によるリソース構築(Resource by Collaborative Contribution(RbCC))」という枠組みで、評価型タスクとリソース構築を同時に進めています。
SHINRA2020-MLは森羅プロジェクトの評価型タスク(shared-task)では初めてのテキスト分類タスクで、NTCIR-15のタスクの一つとして実施し、30言語のWikipedia項目のページの分類に取り組みます。
[タスク紹介ビデオ](約11分:英語)
Introduction of SHINRA2020-ML task (categorization of 30-language Wikipedia into ENE)
このタスクは30言語のWikipediaページを、分類済の日本語記事(92万項目)と対象言語の対応するページへの言語間リンクを利用して、名前のオントロジーである拡張固有表現(Extended Named Entity, 以下ENE) (ver.8.0) の約220カテゴリに分類するタスクです。
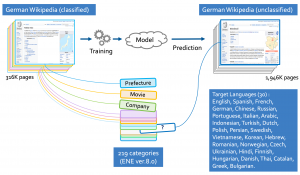 [SHINRA2020-ML全体図]
[SHINRA2020-ML全体図]
参加者は1つ以上の対象言語を選び、分類済の日本語ページから言語間リンクで対応づけられたWikipediaページをトレーニングデータとして、残りのリンクのない未分類ページの自動分類を行います。
例えばドイツ語の場合、2,263Kページの内、日本語ページからの言語間リンクがある275Kページを(少しノイズのある)分類済のトレーニングデータとして、残りの未分類の1,988Kページに対して自動分類を試みていただきます(他の言語のデータ数については、統計情報のページをご覧下さい)。
-
- 分類の対象データとして各言語のWikipediaのDumpデータを配布します。全ての対象データ(ドイツ語の場合は226万項目)の分類結果を提出していただきます。
- 評価には対象データの一部を利用します。
- 全ての参加者によって提出されたデータが公開され、アンサンブル学習などによるリソース構築に挑戦することができます。
対象言語
英語、スペイン語、フランス語、ドイツ語、中国語、ロシア語、ポルトガル語、イタリア語、アラビア語、インドネシア語、トルコ語、オランダ語、ポーランド語、ペルシア語、スウェーデン語、ベトナム語、韓国語、ヘブライ語、ルーマニア語、ノルウェー語、チェコ語、ウクライナ語、ヒンドゥー語、フィンランド語、ハンガリア語、デンマーク語、タイ語、カタルーニャ語、ギリシャ語、ブルガリア語
タスク参加にご興味のある方はこちらもお読み下さい
背景
ウィキペディアは、多くのエンティティ(項目)で構成されています。これは、多くのNLPタスクで利用できる優れた知識リソースです。こうした知識を最大限に活用するには、自然言語処理によってWikipediaから作成されたリソースを推論、意味解析、またはその他の目的のために構造化する必要があります。 DBpedia、Wikidata、Freebase、YAGO、Wikidataなどの現在の構造化されたナレッジベースは、主にボトムアップのクラウドソーシングによって作成されており、ナレッジベースに大量の望ましくないノイズが含まれています。私達は、ナレッジベースの構築は、よりクリーンで価値がある構造となるよう、ボトムアップではなくトップダウンで定義する必要があると考えています。既存の煩雑なウィキペディアカテゴリの代わりに、明確に定義されたきめ細かいカテゴリを用意する必要があります。詳細な固有表現階層のいくつかの定義の中で、拡張固有表現(ENE)は約200の階層カテゴリを持つ明確に定義された名前のオントロジーであり、各カテゴリに対して属性のセットが定義されています。
森羅プロジェクトの最終目標は、属性を含むウィキペディアの知識を構造化することですが、最初のステップとして、属性値を抽出する前に各ウィキペディア項目をENEに分類する必要があります。 SHINRA2020-MLタスクの目的は、30言語のWikipediaページをENE (ver.8.0)のカテゴリに分類することです。 すでに日本語ウィキペディアの主要なページ、92万ページをENE (ver.8.0)カテゴリに分類しています。 これにより、言語間リンクを使用して、30言語のトレーニングデータを作成可能です(ドイツ語版Wikipediaへは32万ページ。詳細は統計情報を参照)。 したがって、SHINRA2020-MLでの実際のタスクは、30言語について、このトレーニングデータを使用して残りの項目を分類することです。
このプロジェクトの目標は、参加したシステムを比較し、どのシステムが最高のパフォーマンスを発揮するかを確認するだけでなく、参加したシステムの出力を使用してナレッジベースを作成することです。 システムの成果を収集し、可能な限り正確にナレッジベースを作成するために、最先端のアンサンブル学習テクノロジーを利用できます。
データライセンス
これらのコンテンツの利用はCC BY-SA 3.0にしたがいます。詳しくは Wikipedia:ウィキペディアを二次利用するをご覧ください。
Organizers
Organizersページをご覧ください。