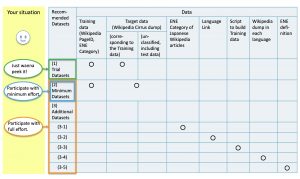
状況に応じて適切なデータセットをお選びください。
-
とりあえず見てみたい
とりあえずどんなものか見てみたい、という方は (1)Trial Datasets をダウンロードして下さい。このデータセットには(2)Minimum Datasetsの一部が含まれています。
-
なるべく手間をかけずにタスクに参加したい
タスクの参加に必要なデータのみで参加したい方は対象言語の (2)Minimum Datasets をダウンロードして下さい。
-
最大限の努力をしてタスクに参加したい
労力を惜しまず、全力でタスクに参加したい方は、タスク参加に必要な(2)Minimum Datasetsに加えて、(3)Additional Datasets からもお好きなデータをダウンロードしてください。
データサイズが大きく、環境によっては一度にダウンロードするのが難しい場合も考えられますので、様々なデータセットをご用意しています。
データのダウンロードが難しい場合は、USBメモリースティックの配送も行います。配送を希望される方は shinra2020ml-info _(at)_ googlegroups.com宛にメールでお知らせいただければ全てのデータ ( (2)Minimum Datasets と (3)Additional Datasets)入りのUSBメモリースティックをお送りします。 代金は1万円程度を予定しています。
(1) Trial Datasets
このデータセットは(2) Minimum Datasets の一部です。カテゴリ分類済のトレーニングデータと、ターゲットデータのWikipediaダンプ(Cirrus Dump)のうちトレーニングデータに対応する部分が含まれています。
想定している方:
-
-
- 参加するかどうか決める前にデータをみてみたい方
- とりあえず学習を試したい方
-
![]()
(2) Minimum Datasets
このデータセットにはカテゴリ分類済のトレーニングデータと、ターゲットデータのWikipediaダンプ(Cirrus dump)全体が含まれています。
想定している方:
-
-
- 参加を決めた方
-
![]()
(3) Additional Datasets
上記(1)、(2)の他に、以下のデータセットがあります。自分でトレーニングデータを作りたい場合は(3-1)、(3-2)、(3-3)をご利用ください。
- (3-1) 拡張固有表現の分類付きの日本語Wikipedia項目
- (3-2) 言語間リンク
- (3-3) 上記の(3-1)と(3-2)からトレーニングデータを作成するスクリプト
- (3-4) 31言語のWikipedia ダンプデータ
- (3-5) 拡張固有表現定義(Extended Named Entity Definition)
ただし、これらのデータセットを使うことでパフォーマンスが必ず向上するとは限りません。
(3-1) 拡張固有表現の分類付きの日本語Wikipedia項目
拡張固有表現 (ver.8.0)の分類付きの日本語Wikipediaページです。
![]()
(3-2) 言語間リンク
言語間リンクは、JSONデータの形式です。MediaWikiの提供しているSQLダンプをクリーンアップしたもので、タスクに必要なページIDを含めています。
![]()
・ヒンドゥー語の言語間リンクは、SQLになかったため、JSONのヒンドゥー語への言語間リンクから作成しています。
(3-3) トレーニングデータ作成用スクリプト
(3-1)及び(3-2)のデータからトレーニングデータを作成するためのスクリプトです。
(3-4) 31言語のWikipedia ダンプデータ
Wikipediaダンプは以下のフォーマットがあります。
- 1) Wiki Dump
- Wikipedia記事のXML形式のダンプデータ.
- 2) Cirrus Dump
- Elasticsearch用のWikipediaダンプデータ。記事の他に検索用の情報も含みます。XMLタグが除かれ、NLPでは使いやすいデータです。
ファイルには以下の3タイプがあります。
- (a) wikidump
- Wikipedia記事のXML形式のダンプデータ。
- (ファイル名) XXwiki-yymmdd-pages-articles.xml.bz2
- (b) cirrusdump-content
- Wikipediaの標準名前空間の百科事典記事。
- (ファイル名) XXwiki-yymmdd-cirrussearch-content.json
- (c) cirrusdump-general
- Wikipediaの標準名前空間以外も含めたページ。talkページや, テンプレートなども含みます。
- (ファイル名) XXwiki-yymmdd-cirrussearch-general.json
・英語(en)、アラビア語(ar)、ベトナム語(vi)については, (c)cirrusdump-general のデータに(b)cirrusdump-contentの全てのダンプデータが含まれています。
ダウンロード方法は以下のいずれかをお選びください:
- 全言語について一括ダウンロード → (3-4-1) All Languages
- 各言語毎にダウンロード → (3-4-2) Each Language
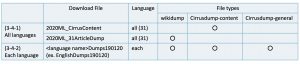
(3-4-1) All languages
31言語全てのデータを含むファイルを一括でダウンロードします。
ファイルタイプは(a)wikidumpと(b)Cirrusdump-contentのいずれかを選択できます。
![]()
(3-4-1-1) All languages (split files)
31言語のWikipedia Dump(2020ML_31ArticleDump(52GB))を4分割したファイルです。全ての分割ファイルを結合し、得られたファイルをご利用下さい。
$cat 30wikidump_articles.tar.bz2-* > 30wikidump_articles.tar.bz2
![]()
(3-4-2) Each Language
各言語毎にファイルをダウンロードします。一部の言語を対象にタスクに参加する場合におすすめです。ファイルタイプは(a)wikidump、(b)cirrusdump-content、(c)cirrusdump-generalが全て含まれています。
![]()
(3-4-2-1) Each language (split files)
英語のWikipediaの各種ダンプデータ(EnglishDumps190120(86GB))を5分割したファイルです。全ての分割ファイルを結合し、得られたzipファイルをご利用下さい。
$ cat English.zip-* > English.zip
![]()
(3-5) 拡張固有表現定義(Extended Named Entity Definition)
拡張固有表現定義(Extended Named Entity Definition) ver.8.0 [JSON]
ライセンスについてはこちらをご確認下さい。
なお、拡張固有表現の概要についてはこちら、ver.8.0についてはこちらをご参照下さい。
データライセンス
これらのコンテンツの利用はCC BY-SA 3.0にしたがいます。詳しくは Wikipedia:ウィキペディアを二次利用するをご覧ください。