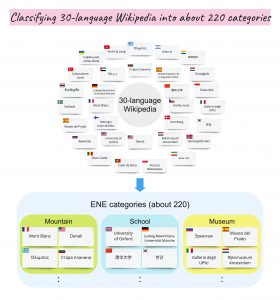
This is a task to classify 30 language Wikipedia pages into about 220 fine-grained Named Entity categories, with a huge training data (i.e. more than 100K pages).
Schedule
Data release: Mar 2021
Kick-off meeting: May 25 2021 [slides] [video]
Leaderboard open: TBA
Result submission deadline: Nov 15 2021
Evaluation results due back to participants: Nov 30 2021
Final report & meeting: Dec 2021
Introduction
- SHINRA2021-ML Kick-off meeting(2021/6/1)
- SHINRA Project Overview at RIKEN AIP Open Seminar, 2021/02/17 [slides]
- Overview of SHINRA2020-ML Task (NTCIR-15) [paper], [slides], [poster]
SHINRA is a resource creation project aiming to structure the knowledge in Wikipedia for machine to manipulate. We have been hosting shared tasks to make the system results (submitted runs) open to public and utilize them to create knowledge resources under a scheme called “Resource by Collaborative Contribution (RbCC)”.
As a first step toward the structuring, a series of shared task called SHINRA ML started in 2020 to tackle the challenge of classifying 30-language (*1) Wikipedia pages in about 220 fine-grained Named Entity categories. SHINRA2020-ML was carried out as one of the NTCIR-15 tasks and we received the official submission results from 10 participant groups and a total of 185 leaderboard submissions.
We would like to hold the same task in 2021 (SHINRA2021-ML) to improve even more on the accuracy and coverage of the data.
Main changes from SHINRA2020-ML are as follows:
- You can participate only in Leaderboard. (If you have limited computing resource or little time, please consider trying the leaderboard!!)
- You have an option to utilize the system results of SHINRA2020-ML. In the official evaluation of the subtasks, we will distinguish between the submissions from systems as to whether they use the SHINRA2020-ML system results or not and evaluate them separately.
- SHINRA2021-ML will be carried out independently from NTCIR due to the task schedule.
Task
The task is to classify 30-language Wikipedia pages into about 220 fine-grained Named Entity categories defined in the Extended Named Entity (ENE) taxonomy (ver.8.0) (a four-layer ontology for names, time, and numbers).
You are expected to select one or more target languages, and for each language, run the system to classify the entire pages provided as a Wikipedia dump.
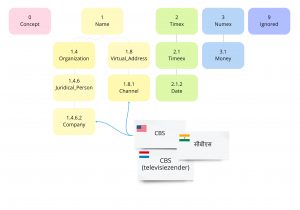
Each page should be classified into one or more of the leaf (bottommost) categories in the four-layer ENE taxonomy (ver.8.0). For example, if the Wikipedia page titled ‘CBS‘ is to be classified into “1.4.6.2: Company” and “1.8.1: Channel“, systems are expected to estimate both categories correctly.
 NOTICE:
NOTICE:
- The categorization has to be done ONLY at the leaf categories (eg. “1.4.6.2: Company“), instead of intermediate categories (eg.”1.4.6: Jyridical_Person” or “1.4: Organization“) Please check the lists of intermediate categories (47) and leaf categories (221).
- Disambiguation pages, redirects, and the pages which do not belong to Wikipedia main space should be classified into “9: IGNORED“.
- If the format of a target Wikipedia page is invalid, for example, no namespace is specified, please just ignore the data.(eg. ‘_id’:”AVQXnGmF62ewIKYZMTMQ” )
Datasets
We will provide the training data for 30 languages, created by the combination of the categorized Japanese Wikipedia of 920K pages and Wikipedia language links for 31 languages. We also provide SHINRA 2020-ML system results, Wikipedia data in various forms and other datasets.
In order to get the data, please create SHINRA account at SHINRA: Sign in page to download the data from SHINRA2021-ML: Data Download. You can download the data regardless of the task participation. (You are regarded as participants of the task only when you submit your run results for any of the subtask.) As for the data format, please refer to SHINRA2021-ML: Data Formats.
If you use the SHINRA2020-ML system results, pre-trained models, or some external information for the task, be sure to indicate what resources you used in the submission form and the system description report.
Submission and Evaluation
Submission
- You should submit the run results for the entire Wikipedia pages including training data for each target language. For each language, you can submit up to three runs based on different methods.
- The submission format is the same as that of SHINRA2020-ML. Please see: SHINRA2021-ML: Data formats.
- If you use the SHINRA2020-ML system results, pre-trained models, or some external information for the task, be sure to indicate what resources you used in the submission form and the system description report.
- For details about results submission (eg. naming of files and submission form), please see SHINRA2021-ML: Results Submission.
Evaluation
- Your runs will be evaluated with the test set hidden among the target data.
- We will evaluate the performance of systems on multi-label classification using the micro average F1 measure, i.e., the harmonic mean of micro-averaged precision and micro-averaged recall. The distribution of category in the test data may differ from that of other task data.
- In the official evaluation, we will distinguish between the submissions from systems as to whether they use the SHINRA2020-ML system results or not and evaluate them separately.
- A system is expected to classify each page into one or more of the ENE (ver.8.0) categories correctly. If the estimated category is not an exact match, the system will not get score for that.
- Notice that the ENE_ids are evaluated regardless of the scores.
Participation procedures
If you are interested in participating in the subtasks, please follow the steps below.
| step | description |
|---|---|
| 1. Account Creation and Data Download | Create SHINRA account at SHINRA:Sign in page and download SHINRA2021-ML datasets from SHINRA2021-ML: Data Download. |
| 2. Result Submission | Submit run results for the target data using SHINRA2021-ML submission form. See SHINRA2021-ML: Results Submission for details. |
| 3. Evaluation | Get evaluation results. |
| 4. Reporting | Final report meeting. |
Notice:
To download the task data, you need to sign up for a SHINRA account at SHINRA:Sign in page.
-Once you create the account, you can download the data from SHINRA2021-ML: Data Download regardless of the task participation. (You are regarded as participants of the task only when you submit your run results for any of the subtask.)
-Your download will be deemed to have accepted to subscribe shinra2021-ml-all@googlegroups.com mailing list and get the latest information of the task.
Misc
References
- SHINRA project: Overview and SHINRA2021-ML Task (RIKEN AIP Open Seminar #13, 2021/02/17) [slide], (video) [English (8:30-26:01)], [Japanese (1:09:47-1:22:42)]
- Research Talk: “Reduce of target data to be predicted in resource construction shared-task using active sampling”.(RIKEN AIP Open Seminar #13, 2021/02/17)
[slide], [video] - Overview of SHINRA2020-ML Task (NTCIR-15)
[paper], [slide], [poster] - Papers on SHINRA2020-ML
- Statistics of Wikipedia in 31 Languages
Data License
Reuse of Wikipedia contents are licensed under the CC BY-SA 3.0. For details, please check Wikipedia: Reusing Wikipedia content.
Contacts
- Slack: http://shinra2021-ml.slack.com/ [Invitation link]
- Google groups:
- Community:
shinra2021-ml-all@googlegroups.com (for anyone interested)
shinra2021-ml-participants@googlegroups.com (for task participants) - Contact: shinra2021ml-info@googlegroups.com
- Community: