新着情報
- 森羅2023のページを公開しました。ぜひタスク参加をご検討下さい。(2023/03/10)
- 「構造化知識を使った言語処理応用」ワークショップ ~森羅2022最終報告会~のページで資料(スライド、動画)を公開しました。(2023/1/20)
- 森羅プロジェクトに興味・関心を持たれた方、参加してみたい方は森羅slackでお気軽にお尋ねください。(2023/01/18)
目次
森羅プロジェクト2021紹介ビデオ
「森羅プロジェクト」はWikipediaの知識を拡張固有表現に基づき、多くの方の協働の元で構造化しようという「協働によるリソース構築(Resource by Collaborative Contribution)」のプロジェクトです。
Wikipediaの構造化 & RbCC
クラウドソースによって構築・更新が行われているWikipediaには、他の百科事典にはない、圧倒的な量の項目が収録されています。しかしながら、これらの項目は、あくまで人が閲覧するための構造しか持っておらず、機械可読な形で表現されているとは言えません。「森羅プロジェクト」ではこのようなWikipedia項目を、機械可読な構造に変換する「構造化」を目指しています。
具体的には、言葉の分類体系である拡張固有表現の各カテゴリーに設定されている属性情報をWikipedia記事中から抽出する評価型ワークショップを開催し、参加者の出力結果を統合することで構造化された知識を構築していきます。このやり方を「協働によるリソース構築(Resource by Collaborative Contribution (RbCC))」と名付け、多くの方の協力で進んでいくプロジェクトです。
3種類のタスク
このプロジェクトの最終ゴールは構造化されたWikipediaを構築することですが、このためには3つの種類のタスクを実現しなければいけません。分類タスク、属性値抽出タスク、属性値リンキングタスクです。
分類タスク: Wikipedia項目を拡張固有表現のカテゴリーに分類するタスクです。日本語では、運営者側で機械学習を利用した分類したものを専門家がチェックし、ほぼ完璧なWikipedia項目の分類を終了させています。多言語(30ヶ国語)では、この日本語のリソースを利用し、RbCCのスキームで分類タスクを行います。SHINRA2020-MLに続き、今回はSHINRA2021-MLを実施します。
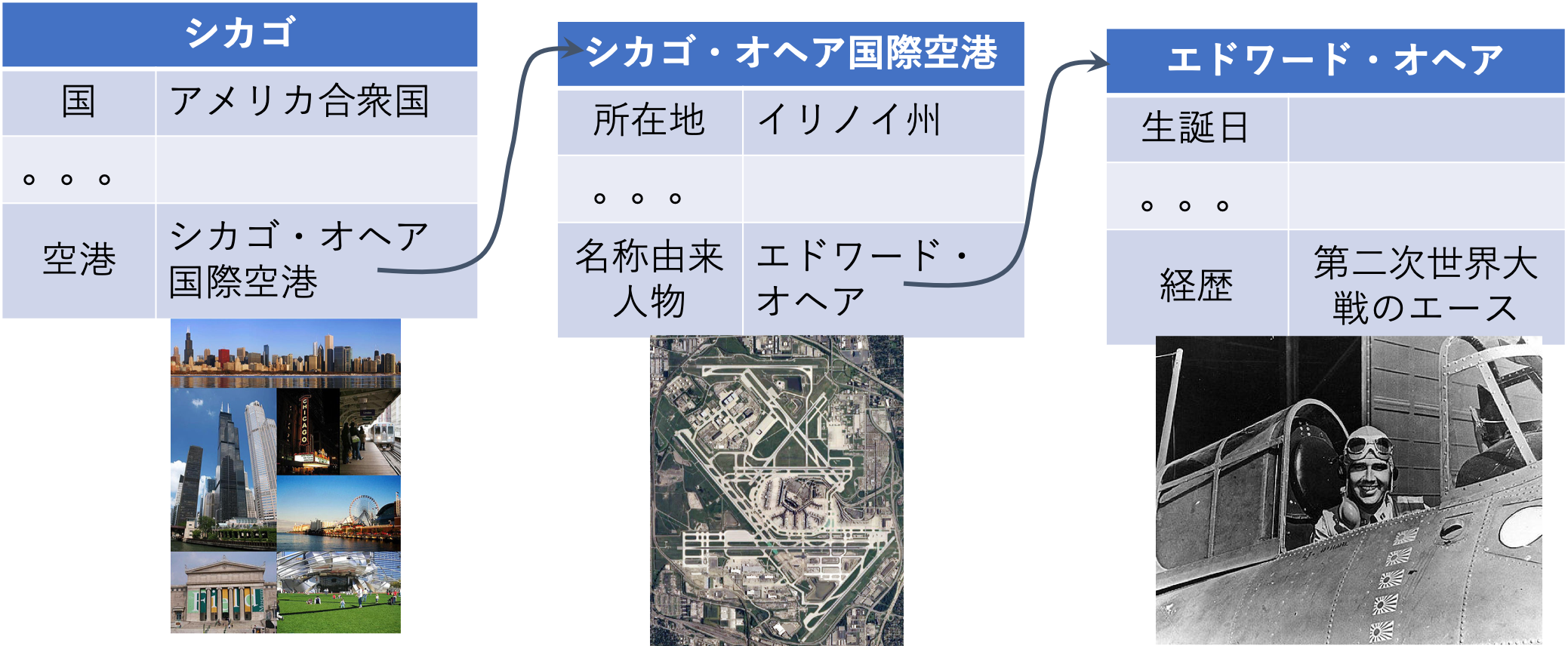
属性値抽出タスク: 各Wikipedia項目に対し、各カテゴリーごとに設定された属性の値を抽出するタスクです。日本語タスクにおいて実施されており、SHINRA2018-JPでは5カテゴリーに対して、 SHINRA2019-JPでは追加の30カテゴリーに対して、SHINRA2020-JPでは追加の47カテゴリーに対して実施します。
属性値リンキングタスク: 各Wikipedia項目から抽出された属性の値を対応するWikipedia項目にリンクするタスクです。LinkJPタスクにおいて実施し、SHINRA2021-LinkJPでは7カテゴリーに対して実施します。
実施タスクリスト
- SHINRA2023タスク
- SHINRA2022タスク
- 過去の森羅プロジェクトに行われた分類、属性値抽出、リンキングの3つのタスクを統合したEnd-to-Endタスクと、その構成要素となる3つのサブタスクを開催し、参加者を募集します。
- SHINRA2021-MLタスク
- 30言語のWikipediaページを拡張固有表現に分類するタスクです。SHINRA2020-MLの継続で、さらなる精度向上を目指します。
- SHINRA2021-LinkJPタスク
- 森羅2021-LinkJPはエンティティーの属性値を該当するWikipediaページに紐づけるタスクです。
- SHINRA2020-MLタスク
- 30言語のWikipediaを拡張固有表現に分類するタスクです。トレーニングデータは分類された日本語Wikipediaの項目と日本語から各言語への言語間リンクを利用して作成します。日本語からの言語間リンクがないWikipediaページを分類するタスクです。
- 森羅2020-JPタスク
- 森羅2019に対し新たに施設名、イベント名の47種類の拡張固有表現カテゴリーを加えた82種類のカテゴリーについて、Wikipedia記事中の対応する記述部分にアノテーションを行うタスクです。
- 森羅2019-JPタスク
- 森羅2018に対し新たに組織名、地形名の30種類の拡張固有表現カテゴリーを加えた35種類のカテゴリーについて、Wikipedia記事中の対応する記述部分にアノテーションを行うタスクです。
- 森羅2018-JPタスク
- 5種類の拡張固有表現カテゴリーについて、それぞれのカテゴリーに分類されたWikipedia記事の文書中から、属性値を抽出する抽出タスクです。
データダウンロード
森羅プロジェクトに関するデータのダウンロードができます。
資料ダウンロード
森羅プロジェクトに関するスライドなどの資料のダウンロードができます。
関連研究
森羅プロジェクトの関連研究のページです。
拡張固有表現
森羅プロジェクトで利用されている拡張固有表現のページです。
コンタクト
ご意見、ご質問は以下のMLにお送りください。
-
-
-
- SHINRA2021-ML: shinra2021ml-info (at) googlegroups.com
- 森羅2021-LinkJP: shinra2021linkjp-info (at) googlegroups.com
-
-