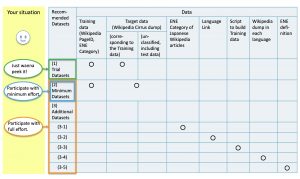
Depending on your situation, select one which fits you best.
-
Just wanna peek it!
If you want to see what it would be like, you can download (1) Trial Datasets, which include parts of (2) Minimum Datasets.
-
Participate in it with minimum effort: you may need only the minimum data
If you are going to participate in the task with required data, please download the (2) Minimum Datasets of the target language.
-
Participate in it with full effort: you can get all data
If you are strongly committed to the task, download any or all of the (3) Additional Datasets in addition to (2) Minimum Datasets.
We arranged various datasets, for the data might be too big to download at a time.
As for the datasets and their corresponding data formats, please check the linked pages listed below.
If it is difficult for you to download a large file over the internet, a traditional mail man will deliver all data to you. Please send email to:
shinra2020ml-info _(at)_ googlegroups.com.
We will ship all the data (including both (2) Minimum Datasets and (3) Additional Datasets) in USB memory stick. It will cost $100.
(1) Trial Datasets
These datasets are part of (2) Minimum Datasets , as examples of the training data classified into categories and the corresponding part of the target data (Wikipedia Cirrus Dump).
These target the following persons:
- Who want to see the data before deciding to participate.
- Who want to make a trial learning for the time being.
![]()
(2) Minimum Datasets
The minimum datasets contain the training data classified into ENE (ver.8.0) categories and the entire target data (Wikipedia Cirrus dump).
These target the following persons:
- Who decided to participate.
![]()
(3) Additional Datasets
You can download any of the following additional data. If you would like to build the training data by yourself, use (3-1), (3-2) and (3-3).
- (3-1) Japanese Wikipedia articles classified into Extended Named Entity categories
- (3-2) Language Link information between Wikipedia of different languages
- (3-3) Script to build the training data using (3-1) and (3-2)
- (3-4) Wikipedia dump data in 31 languages
- (3-5) Extended Named Entity Definition
Notice that these datasets may or may not help you to achieve the maximum performance.
(3-1) Japanese Wikipedia articles classified into Extended Named Entity categories
![]()
(3-2) Language Link information between Wikipedia of different languages
Language Link Information between different languages are available in JSON format. We cleaned the SQL dumps and added page IDs necessary for the task.
![]()
・Notice that Language Link from Hindi is created from Language Link to Hindi in JSON, for there is no Language Link from Hindi in SQL.
(3-3) Script to build the training data using (3-1) and (3-2)
If you would like to build the training data using (3-1) and (3-2) by yourself, the script is available at the following page:
(3-4) Wikipedia dump data in 31 languages
Wikipedia dumps are available in the following formats.
- 1) Wiki Dump
- XML format dump data of Wikipedia articles.
- 2) Cirrus Dump
- Wikipedia dump data for Elasticsearch. It includes not only articles, but also information for search purposes. In general, XML tags are removed and easier to be treated for NLP purposes.
There are three types of files.
- (a) wikidump
- XML format dump data of Wikipedia articles.
- (file name) XXwiki-yymmdd-pages-articles.xml.bz2
- (b) cirrusdump-content
- Encyclopedia article pages in Wikipedia Main name space.
- (file name) XXwiki-yymmdd-cirrussearch-content.json
- (c) cirrusdump-general
- Wikipedia pages in any name space, including talk pages, templates, etc.
- (file name) XXwiki-yymmdd-cirrussearch-general.json
As for English(en), Arabic(ar) and Vietnamese(vi), (c) cirrusdump-general includes all the article dumps of (b) cirrusdump-content.
You can download either of the followings:
- all 31 language data at one time → (3-4-1) All Languages
- each language data at each time → (3-4-2) Each Language
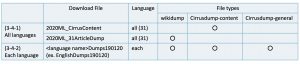
(3-4-1) All languages
These files contain all the data for all 31 languages. So, these are very big files.
![]()
(3-4-1-1) All languages (split files)
Parts of 2020ML_31ArticleDump(Wikidump, 52GB) split across 4 files. Please concatenate all 4 parts into one file.
$cat 30wikidump_articles.tar.bz2-* > 30wikidump_articles.tar.bz2
![]()
(3-4-2) Each Language
These files contain all the data for each language. It is easier to download if you are planning to participate in a part of the 30 languages.
![]()
(3-4-2-1) Each language (split files)
Parts of EnglishDumps190120(Wikipedia dumps (Wikidump and Cirrusdump), 86GB)) split across 5 files. Please concatenate all 5 parts into one zip file.
$ cat English.zip-* > English.zip
![]()
(3-5) Extended Named Entity Definition
Extended Named Entity Definition v8.0 is available at:
ENE Definition v8.0.
Please check the license.
Also, you can understand the whole picture and browse versions of the Extended Named Entity at Extended Named Entity page.
Data License
These contents are licensed under the CC BY-SA 3.0. For details, please check Wikipedia: Reusing Wikipedia content.